The PageRank Citation Ranking: Bringing Order to the Web
Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd, Stanford University. November, 1999
(주: 구글의 창업자인 세르게이와 기타 등등-_-이 쓴 논문입니다. 구글의 prototype도 등장합니다.)
Problem Definition
웹 페이지들은 매우 많고, 주제도 다양하며 내용도 100% 신뢰할 수 있는 것은 아니다. 그런 문서들의 집합에서 search engine은 다양한 방법으로 개선되고 있다. 그런데, 웹 문서는 flat한 document들과는 달리 hypertext로 이루어져있기 때문에 link structure나 link text등의 부가적인 정보를 제공하게 된다. 이 paper에서는 웹의 link structure를 이용해 모든 웹 페이지에 global한 "importance" ranking을 매기려고 한다. 이 랭킹은 이후, PageRank라고 한다.
Their Solution
많이 링크되어 있는 페이지는 그렇지 않은 페이지보다 더 "중요"하며, 중요한 페이지로부터의 하나의 링크를 갖고 있는 페이지는, 덜 중요한 페이지로부터 많은 링크를 갖고 있는 페이지보다 중요하다.
즉, 페이지는 그것의 backlink(in-edge)의 랭크의 합이 높을 수록 높은 랭크를 가진다. 이것은 많은 backlink를 갖는 것과, 다른 것들보다 더 중요한 몇 개의 backlink를 갖는 두 가지 경우를 모두 cover한다.
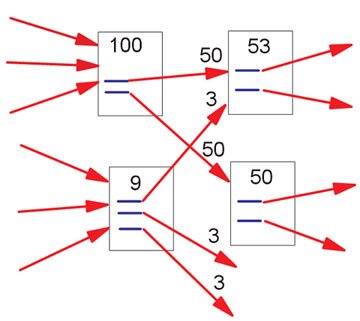
위의 그림은, rank의 계산에 대한 간단한 예이다.
Strong Points
페이지의 contents를 전혀 고려하지 않고 단순히 link structure만을 갖고 더 중요한 페이지를 알아내는 것은 machine의 입장에서 상당히 효율적이다.
상당히 정확하게 common case를 구해낼 수 있으며, 이것은 '지식이 잘 정리된' 사이트보다 유저에게 효용 가치가 높다.
scalable하다. indexing 하고 있는 페이지에 대해 대수적으로 연산 시간이 증가한다.
검색 결과를 조작하려는 시도에 대해서 강한 내성을 갖는다.
Weak Points
machine은 contents를 전혀 이해하지 않는다.
유행을 반영하는 속도가 빠를 것 같지 않다. 이전에 쌓아놓은 페이지에 대한 랭크는 크게 변하지 않으며 느린 속도로 올라가고, 최근에 등장하기 시작한 이슈는 0에서부터 빠르게 올라가기 때문에 그 차이를 좁히는데 어느 정도의 시간이 필요할 것으로 생각된다.
이미지에 대한 링크의 경우 link text에 대한 정보를 얻을 수 없기 때문에 (well-defined된 HTML이 아닌 경우에) 어떤 식으로 관련을 짓는지에 대한 언급이 없다. - 논문의 focus가 full-text searching이므로 문제는 아니지만, 궁금하다.
New Idea
XHTML 등 점점 구조화된 문서가 보급화됨에 따라 문서의 semantic을 어느 정도 이해하는(Semantic Web처럼 완벽한 이해를 추구하는 것이 아니라, 어느 것이 문서에서 중요하고 덜 중요한 의미 정도) 것이 가능해지고 있으며 그러한 경향은 각 문서를 보다 정확하게 연결지어줄 것으로 생각한다. 그것이 PageRank와 결합되면 더 정확하고 연관성 있는 문서를 검색해내는 일이 가능해질 것 같다. 또한 '정확한' 검색이 가능해지면 사람들을 그 쪽으로 더 유도할 수도 있을 것이다.
rank sink를 조정하기 위해서 도입한 E vector를 잘 결정해서 Personalized PageRank를 할 수 있다고 언급한 부분을 응용하면, 특정 분야에 특화된 검색 엔진을 만들어낼 수 있을 것이다. 이것은 수요만 보장된다면 충분히 상업성이 있다. (아마도 google scholar에서 사용하는 E vector는 google에서 사용하는 그거과는 다를 것이다. 논문을 퍼블리싱하는 각 단체들의 사이트들을 중심으로 E vector가 이루어져 있을 것 같다.)
그런 관점에서 개인의 즐겨 찾기가 web 기반으로 관리되고 있는 시점에서(del.icio.us 등) 그것들을 충분히 반영하여 개인화된 searching을 제공할 수 있는 환경이 만들어지고 있다고 할 수 있겠다. 사용자가 보다 관심을 갖고 있는 분야가 어디인지, 그리고 검색어가 들어왔을 때 그 검색어와 사용자가 평소에 관심을 갖는 분야를 매칭시켜 사용자의 목적을 이해하려는 시도는 조만간 실현될 것으로 보인다.
'온라인광고알까기 > 온라인광고전략' 카테고리의 다른 글
| 구글의 경영진 (0) | 2008.05.23 |
|---|---|
| 구글 기술 (0) | 2008.05.23 |
| [키워드제안] 5월의 인기키워드 (0) | 2008.04.19 |
| [키워드제안] 4월 인기키워드 (0) | 2008.04.19 |
| [키워드제안] 1월의 인기 키워드 (0) | 2008.04.18 |


